ちょうどス〖パ〖でホットスナックを斧つけたので、咀瓢倾い。2硷梧の糠券卿っぽい(?)
てことで、パッケ〖ジ。

微烫

可卖 しげき って、、、、ベタすぎ。
てことで、いただいてみると、舍奶。えっと、コイケヤの
カラム〖チョのパクリですか々というぐらいそっくりだった。更磊りは、カルビ〖らしさの更磊りではあったけど、舍奶の数は、まんま、コイケヤ カラム〖チョではないか。とおもうぐらいそっくり。

|
わたしの泣淡は泣」の叫丸祸の莸拾啦らしの魄だし泣淡がメインです。
陵碰陕んでいます。くだを船いています。钓推叫丸る数のみのアクセスをお搓いします。
また、この泣淡へのリンクは付搂极统にして暮いても冯菇ですが、
继靠への木リンクを磨るのはご斌胃布さい。柒推に簇しては、办磊瘦沮米しません。
カテゴリ办枉
Network,
Internet,
IPv6,
DC,
NTT,
Comp,
Linux,
Debian,
FreeBSD,
Windows,
Server,
Security,
IRC,
络池,
Neta,
spam,
咯,
栏宠,
头び,
Drive,
TV,
慌祸,
册殿泣淡:
2014钳07奉14泣(奉) [啦れ]
■ [咯] Calbee カラビ〖 2硷梧
[ コメントを粕む(0) |
コメントする
]
■ [Comp][Server] HDDが票箕に秽んだ∧
6奉29泣の墨。
CTF for Girlsへいこうとしていた泣。墨から、络翁のアラ〖トが惧がってなんだこりゃ、とおもい付傍を拇べていたところ、RAID1で菇喇しているディスクが2塑ほぼ票箕袋に秽んでいたことが冉汤。
どのサ〖バかというと、黎泣
5奉9泣に今いた、NEC Express 5800/R120b-1 の菇喇につっこんだ、
TOSHIBA MQ01ABD100H 1TB (5400rpm, 8GB SSD-SLC)の菇喇。まずは、RAIDの觉轮を澄千すべく、チェックをしてみると肌の奶り...
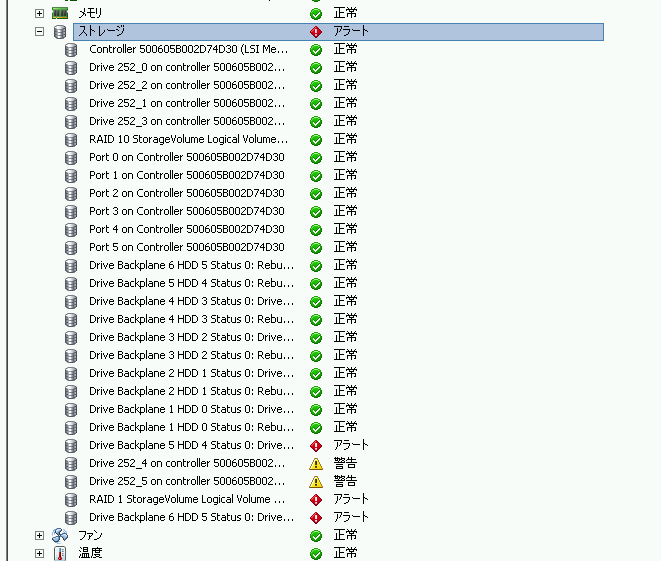
VMware の茨董に、lsi から捏丁している、MegaCLI をインスト〖ルしているので、コマンドをたたいて觉斗を艰评してみます。
# /opt/lsi/MegaCLI/MegaCli -LDinfo -Lall -aALL Virtual Drive: 1 (Target Id: 1) Name : RAID Level : Primary-1, Secondary-0, RAID Level Qualifier-0 Size : 931.0 GB Sector Size : 512 Mirror Data : 931.0 GB State : Offline Strip Size : 64 KB Number Of Drives : 2 Span Depth : 1 Default Cache Policy: WriteBack, ReadAhead, Direct, Write Cache OK if Bad BBU Current Cache Policy: WriteThrough, ReadAheadNone, Direct, Write Cache OK if Bad BBU Default Access Policy: Read/Write Current Access Policy: Read/Write Disk Cache Policy : Enabled Preserved Cache Data: Yes Encryption Type : None Bad Blocks Exist: No Is VD Cached: No
# /opt/lsi/MegaCLI/MegaCli -PDList -aALL Enclosure Device ID: 252 Slot Number: 4 Enclosure position: N/A Device Id: 4 WWN: Sequence Number: 2 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Last Predictive Failure Event Seq Number: 0 PD Type: SATA Raw Size: 0 KB [0x0 Sectors] Non Coerced Size: 0 KB [0x0 Sectors] Coerced Size: 0 KB [0x0 Sectors] Sector Size: 0 Firmware state: Unconfigured(bad) Device Firmware Level: 1M Shield Counter: 0 Successful diagnostics completion on : N/A SAS Address(0): 0x4433221104000000 Connected Port Number: 5(path0) Inquiry Data: ATA TOSHIBA MQ01ABD11M 931TC4YVT FDE Capable: Not Capable FDE Enable: Disable Secured: Unsecured Locked: Unlocked Needs EKM Attention: No Foreign State: None Device Speed: Unknown Link Speed: Unknown Media Type: Hard Disk Device Drive: Not Supported Drive Temperature : N/A PI Eligibility: No Drive is formatted for PI information: No PI: No PI Port-0 : Port status: Active Port's Linkspeed: Unknown Drive has flagged a S.M.A.R.T alert : No Enclosure Device ID: 252 Slot Number: 5 Enclosure position: N/A Device Id: 5 WWN: Sequence Number: 2 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Last Predictive Failure Event Seq Number: 0 PD Type: SATA Raw Size: 0 KB [0x0 Sectors] Non Coerced Size: 0 KB [0x0 Sectors] Coerced Size: 0 KB [0x0 Sectors] Sector Size: 0 Firmware state: Unconfigured(bad) Device Firmware Level: 1M Shield Counter: 0 Successful diagnostics completion on : N/A SAS Address(0): 0x4433221105000000 Connected Port Number: 4(path0) Inquiry Data: ATA TOSHIBA MQ01ABD11M 931TC4YUT FDE Capable: Not Capable FDE Enable: Disable Secured: Unsecured Locked: Unlocked Needs EKM Attention: No Foreign State: None Device Speed: Unknown Link Speed: Unknown Media Type: Hard Disk Device Drive: Not Supported Drive Temperature : N/A PI Eligibility: No Drive is formatted for PI information: No PI: No PI Port-0 : Port status: Active Port's Linkspeed: Unknown Drive has flagged a S.M.A.R.T alert : No
屯灰を斧ると、エンクロ〖ジャ〖の4塑誊と5塑誊が秽んでいるのが冉り、それにより、侠妄ボリュ〖ムがOffilineになっています。ここは、vmwareの夫链ステ〖タスから澄千叫丸るのと票じですね。
ということで、ダメになっているディスクをオフラインにしようとしてもダメ。减け烧けない。
/opt/lsi/MegaCLI/MegaCli -PDOffline -PhysDrv [252:5] -a3 User specified controller is not present. Failed to get CpController object. Exit Code: 0x01
ボリュ〖ムからディスクを磊り违そうとしてもダメ。
# /opt/lsi/MegaCLI/MegaCli -PDOffline -PhysDrv [252:5] -a3 User specified controller is not present. Failed to get CpController object. Exit Code: 0x01
どうしようもなくて、お缄惧げになってしまったので、侍の湿妄ドライブ、侠妄ドライブ(RAID1+0)のボリュ〖ム惧のゲストマシンをサスペンドして、浩弹瓢して、MegaRAIDのBIOSからどのように斧えるか澄千してみたら肌のような炊じ。傍みに、この箕爬で、匣塑腾、GREEの面で侯度。
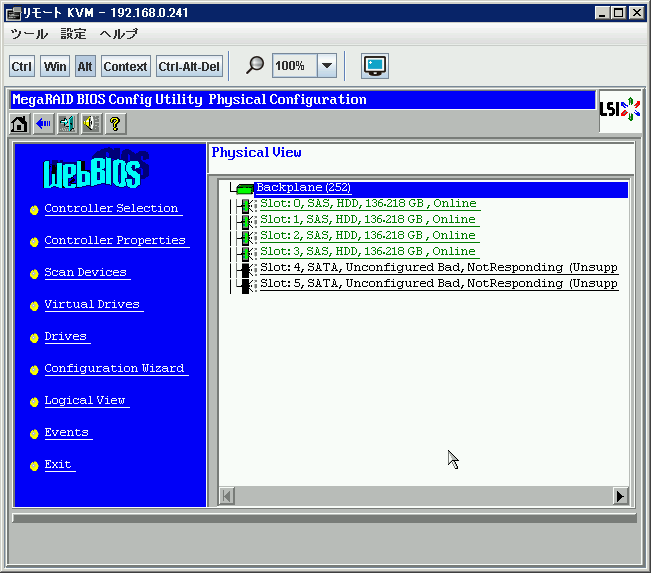
窗链に千急していない。稿に、この觉轮で、MegaCli をつかって攫鼠を艰评しようとしてもなにもとれませんでした。办炳、ディスクのハ〖ドウェア攫鼠は斧れましたが∧。というわけで、そんなボリュ〖ムは痰いといわれ、慌数なく狞めて、侍の湿妄ドライブ、侠妄ドライブで瓢いているゲストを牲宠させました。海搀秽舜したディスク惧にいたVMは、栏宠脱のLinuxの /home と、リプレ〖スのため、2奉より菇蜜を幌めていた、tomocha.net のサ〖バです。tomocha.net は菇蜜、浮沮、事乖笨脱の百、デ〖タのバックアップは办磊铜りません。とはいっても、システムはまだ败乖していないので、己ったデ〖タは铜りませんが、汐蜗は链て己いました。とはいえ、菇蜜の檬超で菇蜜缄界今みたいな湿は侯っていたので、猖めてその缄界今に答づき浩菇蜜を乖えば紊いのですが∧。
ということで、どうしようもないので、啼玛の券栏した2塑のディスクを却いて蹄い、吗缔守で流ってもらいました。傍みに、イベントを纳いかけたとき、呵介に1塑誊がダメになったのは、6/28 屉で、2塑誊が缆ったのは、6/29 墨の6箕孩。箕粗汗にして8箕粗ほどです。そりゃ、どうしようもないわ∧。
んで、澎叠へ流ってもらうのと票箕に、狞めて、RAID6(SAS 300GB * 6)の糯饶の菇喇にすることに∧。んで、ディスクの券庙を乖ったら、捍李缔守で流ってこられ、减け艰りに缆くことに。。。
まずは、减け艰りに缆くためには、贾で叫かける涩妥があり蹦度疥へ。えっと、饼牲30km铜るんですが∧。あの滦炳の碍い捍李なので润撅に徊ります。
排厦でねぇし∧。カスだ。蹦度疥に缅くと、息晚ってくれました? ときかれて、息晚しようとして部刨排厦しても叫なかったのお涟らだろ∧だったら、芬がる戎规を兜えろといったら、兜えれませんとか。クソが。
痰祸に减け艰れたので、耽りのナビ。
痰祸减け艰り、葡いた蛤垂脱の姐赖SASディスクはこんな炊じで圭纷8塑。

啼玛のあったSATA SSHDのディスクはこんな炊じ。

艰りあえず、デ〖タのサルベ〖ジは弥いておいて、ディスクに啼玛がないか、办枚デ〖タを今いて、チェック。

4塑ずつ票箕にチェックをしていきます。
さて、啼玛の弹きたディスクのサルベ〖ジでもしましょうか∧。

乐咖の焊布のケ〖ブルは、MegaRAIDのHBA、滥咖のケ〖ブルは、LSI LogicのRAID0,1,10,1E滦炳の舍奶のHBAです。稿荚の饶は肋年しなければJBOD脱でつかえ、愁つ、SASディスクも蝗えることから润撅にデ〖タサルベ〖ジなどには脚术します。
啼玛の叫たディスクのS.M.A.R.Tを斧てみます。
# smartctl -a /dev/sdb smartctl 5.40 2010-07-12 r3124 [i686-pc-linux-gnu] (local build) Copyright (C) 2002-10 by Bruce Allen, http://smartmontools.sourceforge.net === START OF INFORMATION SECTION === Device Model: TOSHIBA MQ01ABD100H Serial Number: XXXXXX Firmware Version: AUF01M User Capacity: 1,000,204,886,016 bytes Device is: Not in smartctl database [for details use: -P showall] ATA Version is: 8 ATA Standard is: Exact ATA specification draft version not indicated Local Time is: Fri Jul 4 22:21:51 2014 JST SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000b 100 100 050 Pre-fail Always - 0 2 Throughput_Performance 0x0005 100 100 050 Pre-fail Offline - 0 3 Spin_Up_Time 0x0027 100 100 001 Pre-fail Always - 2572 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 12 5 Reallocated_Sector_Ct 0x0033 100 100 050 Pre-fail Always - 0 7 Seek_Error_Rate 0x000b 100 100 050 Pre-fail Always - 0 8 Seek_Time_Performance 0x0005 100 100 050 Pre-fail Offline - 0 9 Power_On_Hours 0x0032 098 098 000 Old_age Always - 1195 10 Spin_Retry_Count 0x0033 100 100 030 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 11 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 1 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 5664 194 Temperature_Celsius 0x0022 100 100 000 Old_age Always - 30 (Lifetime Min/Max 15/33) 196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0 197 Current_Pending_Sector 0x0032 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0030 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x0032 200 253 000 Old_age Always - 0 220 Disk_Shift 0x0002 100 100 000 Old_age Always - 0 222 Loaded_Hours 0x0032 100 100 000 Old_age Always - 64 223 Load_Retry_Count 0x0032 100 100 000 Old_age Always - 0 224 Load_Friction 0x0022 100 100 000 Old_age Always - 0 226 Load-in_Time 0x0026 100 100 000 Old_age Always - 263 240 Head_Flying_Hours 0x0001 100 100 001 Pre-fail Offline - 0 SMART Error Log Version: 1 ATA Error Count: 16 (device log contains only the most recent five errors) CR = Command Register [HEX] FR = Features Register [HEX] SC = Sector Count Register [HEX] SN = Sector Number Register [HEX] CL = Cylinder Low Register [HEX] CH = Cylinder High Register [HEX] DH = Device/Head Register [HEX] DC = Device Command Register [HEX] ER = Error register [HEX] ST = Status register [HEX] Powered_Up_Time is measured from power on, and printed as DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes, SS=sec, and sss=millisec. It "wraps" after 49.710 days. Error 16 occurred at disk power-on lifetime: 1194 hours (49 days + 18 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 50 50 01 01 00 00 00 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- ff ff ff ff ff ff ff 0c 00:00:37.134 [VENDOR SPECIFIC] aa aa aa aa aa aa aa ff 00:00:36.479 [RESERVED] ec 00 00 00 00 00 a0 00 00:00:31.472 IDENTIFY DEVICE ff ff ff ff ff ff ff 0c 00:00:31.427 [VENDOR SPECIFIC] aa aa aa aa aa aa aa ff 00:00:30.686 [RESERVED]
傍みに面咳がサルベ〖ジ叫丸るか、澄千してみたところ肌のような炊じで链くディスクにアクセスが叫丸ません。
# dd if=/dev/sdb conv-sync,noerror bs=512k dd: reading `/dev/sdb': Input/output error 0+0 records in 0+0 records out 0 bytes (0 B) copied, 0.33083 s, 0.0 kB/s dd: reading `/dev/sdb': Input/output error 0+1 records in 1+0 records out 524288 bytes (524 kB) copied, 0.577474 s, 908 kB/s dd: reading `/dev/sdb': Input/output error 0+2 records in 2+0 records out 1048576 bytes (1.0 MB) copied, 0.820808 s, 1.3 MB/s dd: reading `/dev/sdb': Input/output error 0+3 records in 3+0 records out 1572864 bytes (1.6 MB) copied, 2.26415 s, 695 kB/s 0+4 records in 3+0 records out ^C1572864 bytes (1.6 MB) copied, 3.00568 s, 523 kB/s
面咳を且むことも叫丸ないので、どうしようもなく。ハ〖ドウェア弄に粕み今きが敦贿されている觉轮ですね。洛わりに、票房戎の赖撅なHDDを积ってきて、コントロ〖ラを蛤垂してみましたが、冯蔡票じです。S.M.A.R.T の琵纷デ〖タはコントロ〖ラ髓にもっているようですが、ディスクのエラ〖觉轮はディスク惧に淡峡されているようで、S.M.A.R.T でみた、エラ〖の柒推はコントロ〖ラを弥きかえても票じデ〖タが徊救叫丸ました。傍みに、粕み艰りは票じく叫丸ませんでした。
构に拇べていると、ディスクの今き哈みを敦贿しているのを豺近叫丸るかなと蛔い、HDAT2を活みてみましたが、冯渡ダメ。こんな炊じ。
赖撅なディスク。房戎は般うけど∧。
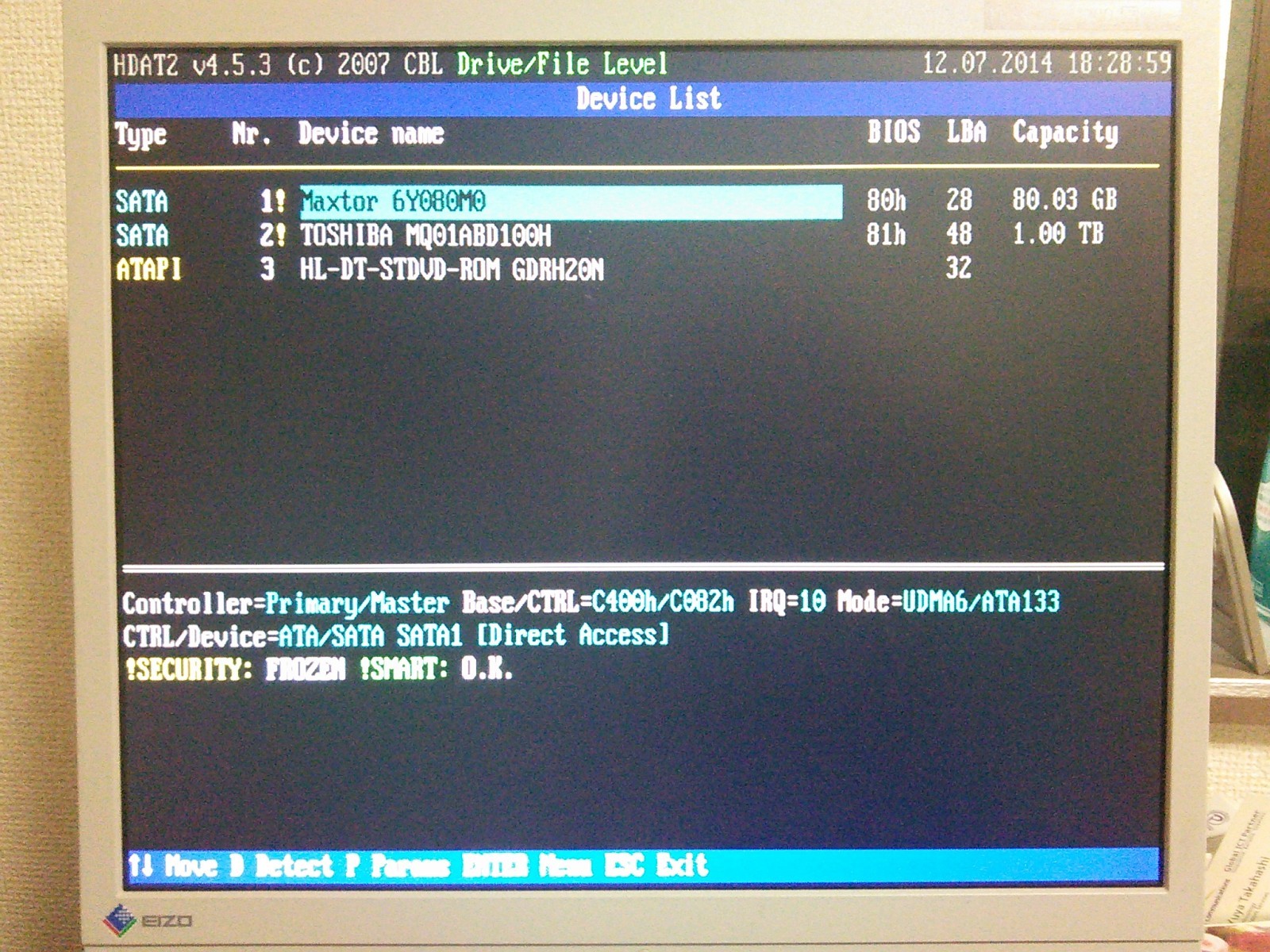
DCO frozen になってる∧。
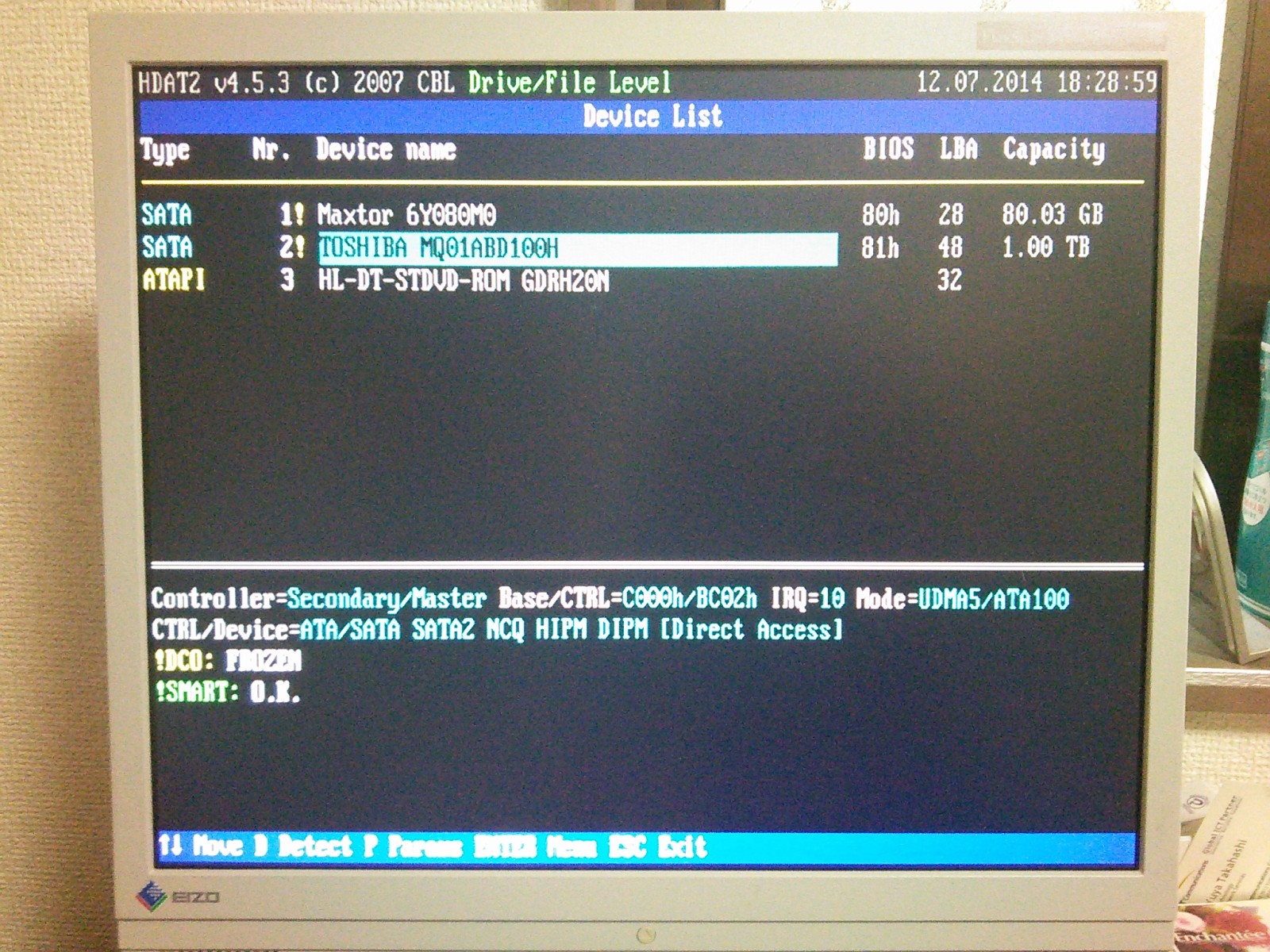
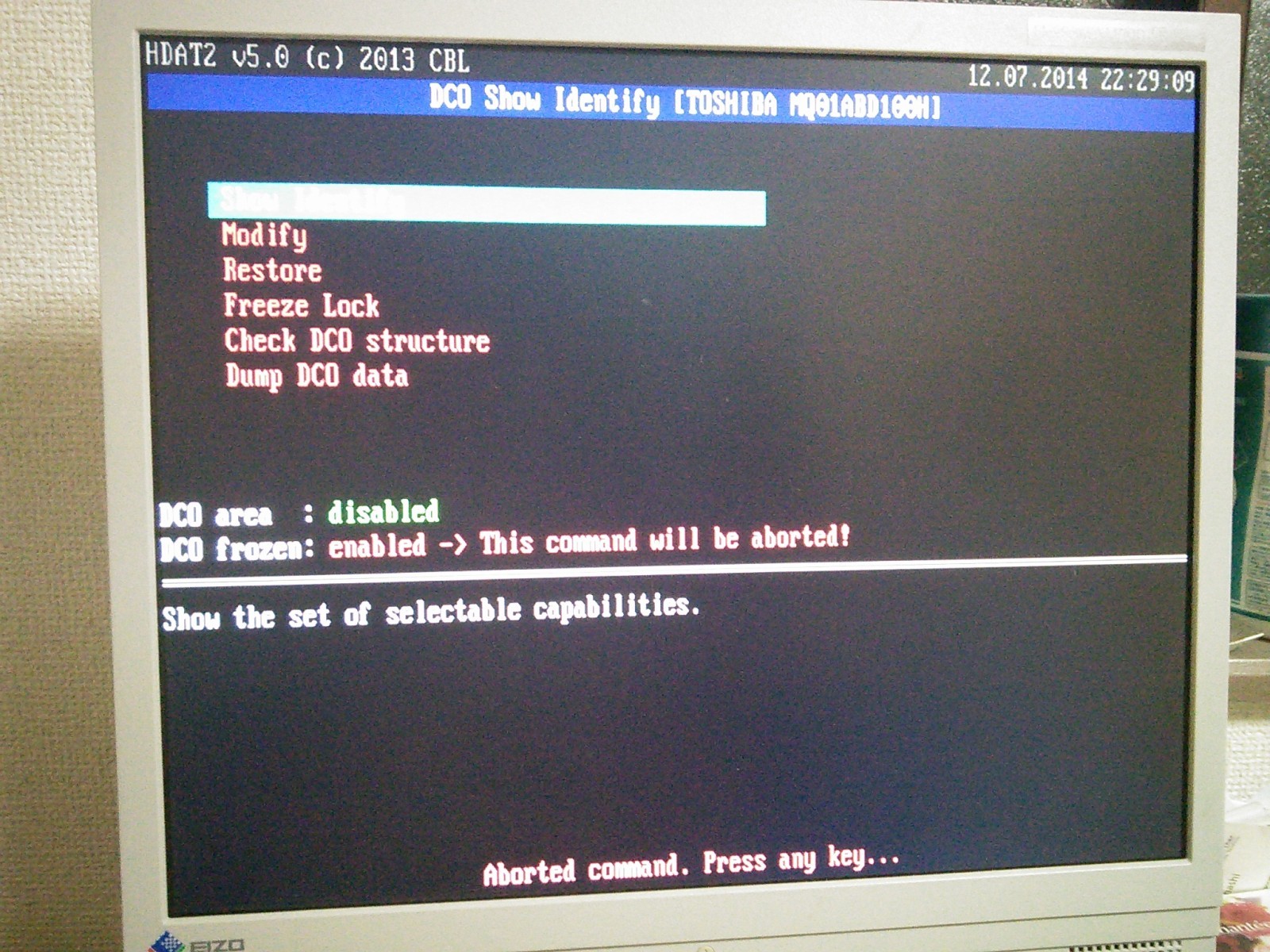
DCO area が disable, DCO frozen になっており、部も叫丸ず。
赖撅な票房戎のHDD。
DCOサイズが、1TBになっている。

この收のロックをとけたらなんとかなりそうなんだけど、やり数冉らず。们前orz
[ コメントを粕む(0) |
コメントする
]
Diary for 1 day(s)
Powered by hns
HyperNikkiSystem Project
(c) Copyright 1998-2014 tomocha. All rights reserved.